Introduction
The goal of this lab was to build on knowledge of classification methods obtained from previous labs by examining advanced classification schemes. Differing from un/supervised classification methods, advanced classifiers use complex decision trees and neural networks to learn from user input and build a classification scheme in an image.
Methods
Part I: Expert System Classification
The first advanced classifier used in this lab was an "expert system". An expert system uses the spectral information from the image to generate a classification scheme, much like un/supervised algorithms, but also as much ancillary data as is available. So information regarding temperature, soil, zoning, population, and a plethora of other information that supplements assessment of the surface features in the image is used to generate a better than minimum threshold classified image.
To begin the expert system classification process, a classified image was brought into ERDAS Imagine and observed. This was done by comparing the classified image to a Google Earth image of the same area. The greatest misclassified fields were lawns and other open grass areas that were classified as agriculture- this was corrected using the expert classification scheme. Through this process, the "urban/built-up" class was split into "residential" and "other urban" as well.
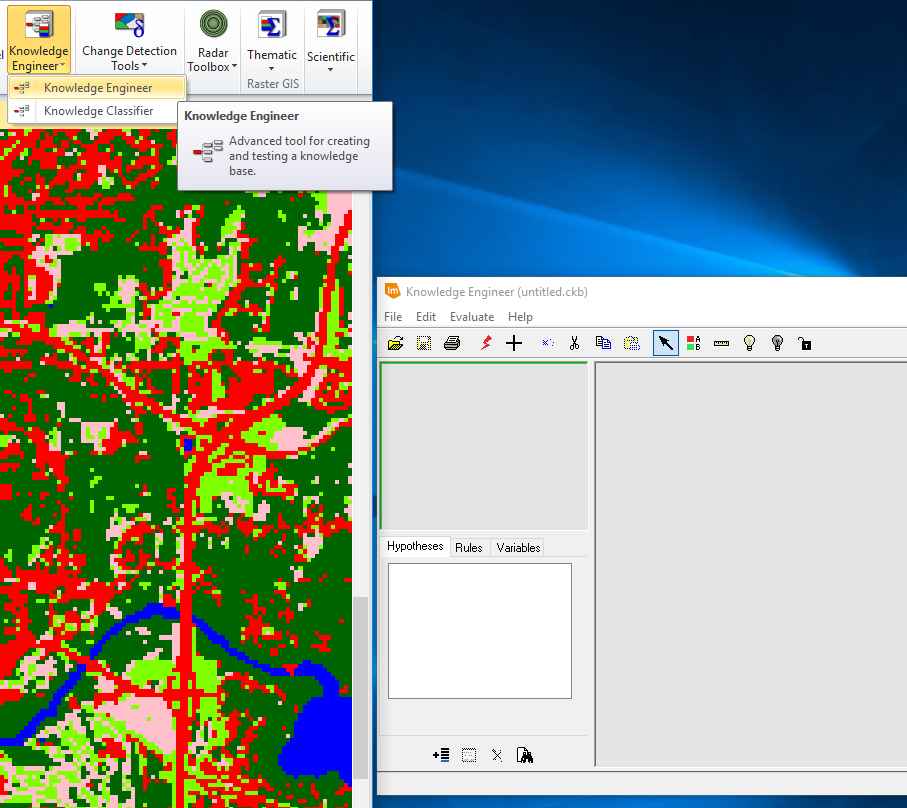
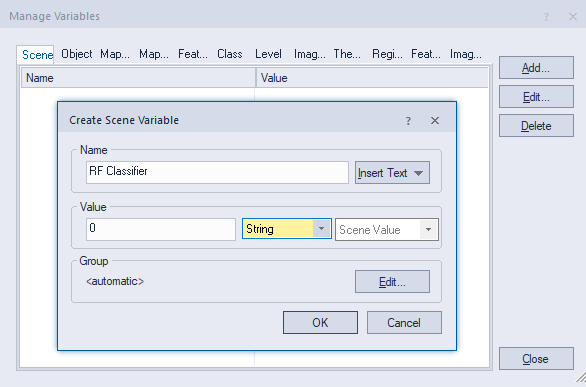
Once the classes needing correction were identified, the
Knowledge Engineer raster tool was used to train the classifier.
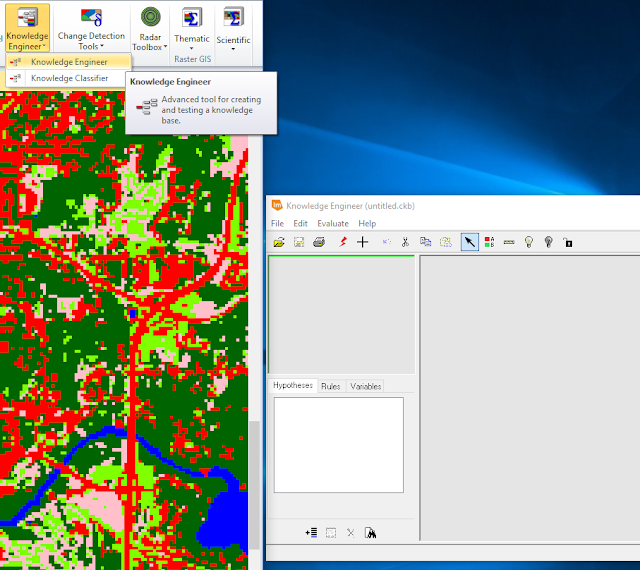 |
| Figure 1: Opening the Knowledge Engineer raster tool. |
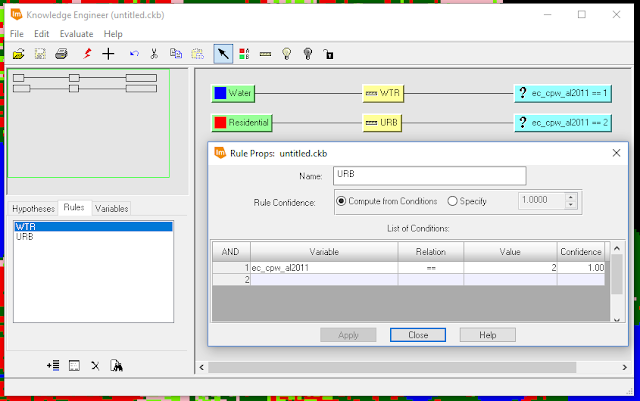 |
| Figure 2: Setting rules for class values within the Knowledge Engineer. |
By creating a "Hypothesis Class" (two of which are shown as the green tabs in Figure 2) for each class in the image and setting the "Rule Props" (shown in "rule props" window in Figure 2) to associate a value with each class in the image, the
Knowledge Engineer established rules for the expert classifier to follow.
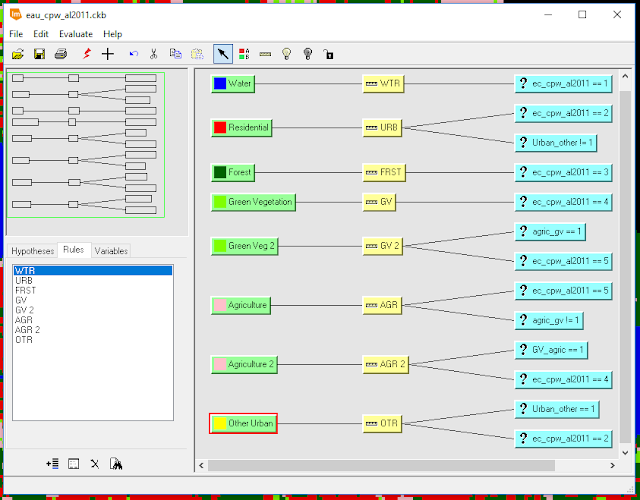 |
| Figure 3: Finalized Knowledge Engineer trainer. |
As shown in Figure 3, every class that was included in the original classified image was included here, but also a few other classes were added ("Green Veg 2", "Agriculture 2", and "Other Urban" hypothesis classes). Also, notice that there are a few classes with two values-- this was a result of a logical operation created in the rules which is what trains the reclassification scheme to choose whether a class is as classified or should be changed using ancillary data (shown as variables in Figure 3 that do not use the image in question "ec_cpw_al2011").
Once the
Knowledge Engineer was finished, the engineer was ran to verify that the trainer was set up properly. The engineer was then used to train the
Knowledge Classifier raster tool.
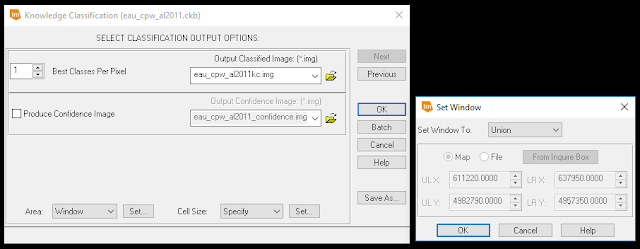 |
| Figure 4: Inputting parameters to the Knowledge Classifier. |
In Figure 4, the output image was given a name and storage location, the "Area" parameter was set to "Union" (shown in the "Set Window" window), and the "Cell Size" parameter was set to 30 x 30. The output image was generated (see
Results section).
Part II: Neural Network Classification
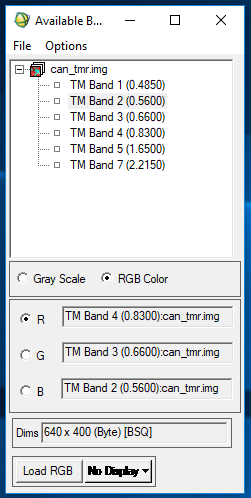
The second part of this lab focused on a different kind of advanced classifier-- the Neural Network classifier. This classification method simulates a network of neural pathways in the human brain. To do this, ENVI software was used. First, an image was brought into the software and the color bands of that image were selected to bring the image into a viewer.
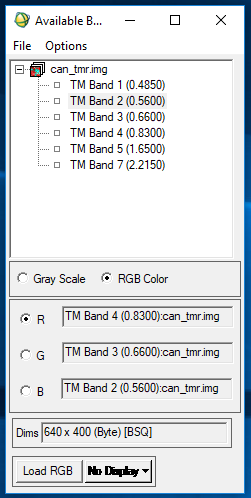 |
| Figure 5: Selecting color band combination to display a false color image. |
Once the color band combination was determined, the next step was to restore the predefined regions of interest (ROIs) within the image; these were displayed as red, green, and blue polygons that overlayed the image.
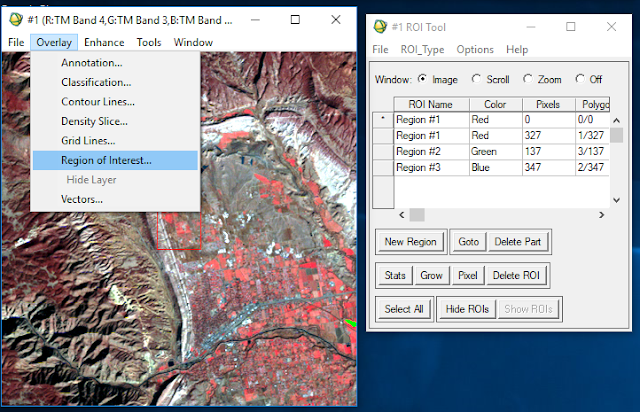 |
| Figure 6: Restoring ROIs. |
Then, the neural network parameters were established
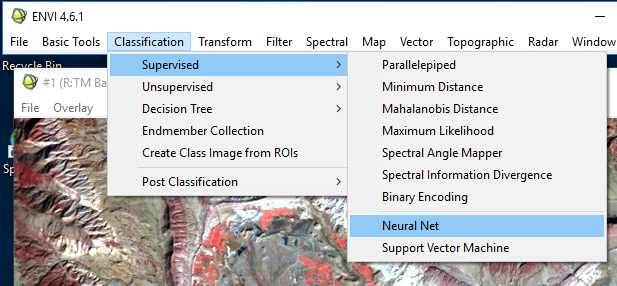 |
| Figure 7: Starting neural network classification. |
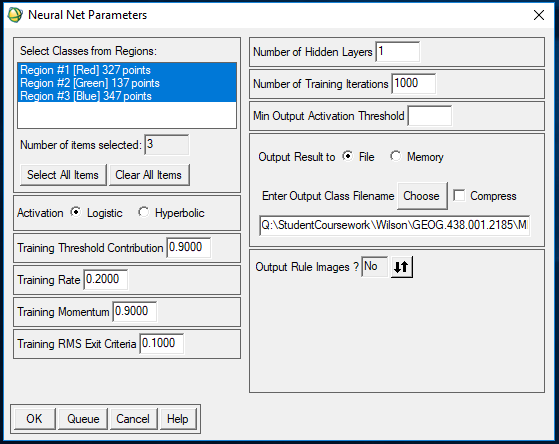 |
| Figure 8: Establishing parameters for neural network. |
In Figure 8, the red, green, and blue regions were selected as classes (these were based on the polygons overlayed in the original image), the activation parameter was set to "logistic", the number of training iterations was set to 1000, the output file was given a name and storage location, and the output rule images parameter was set to "no". This model was then ran and produced an
RMS error by number of iterations plot and a classified version of the input image (see
Results section).
Results
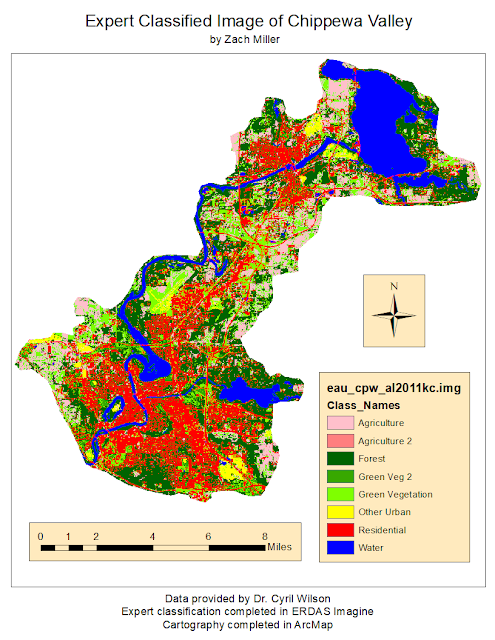 |
| Figure 10: Expert classification result. |
Looking at the results of part one (Figure 10), the image displays a more accurate and detailed classification than the input classified image (Figure 9). The output from the expert system splits the urban/built-up land into residential and other urban, which is distinguishable in many areas within the image-- the Chippewa Valley Regional Airport on mid-west side and Maple Wood Mall on southeast side of the image are good examples of this change. One issue with the expert system output, however, is that the resulting agriculture and green vegetation classes are unintentionally split into two classes which makes the output more confusing in my opinion. On the other hand, this could be useful in determining which areas were changed to agriculture and green vegetation as a result of using the expert system.
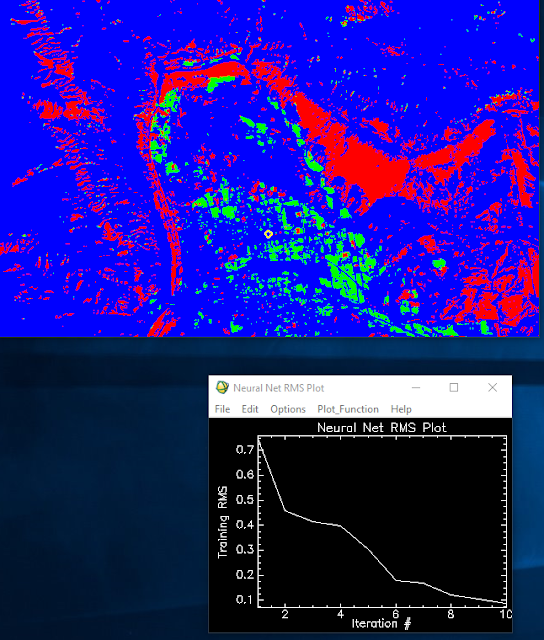 |
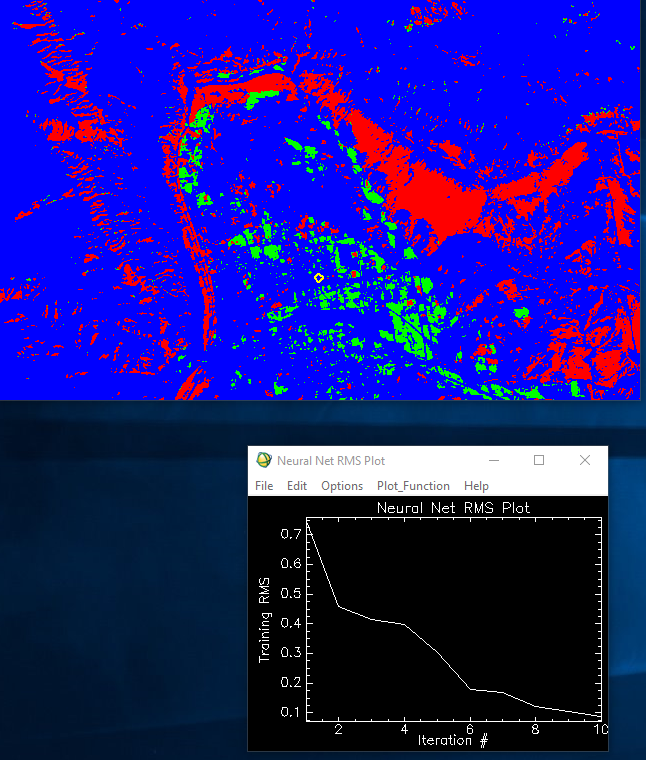
| Figure 11: Neural Network output image and RMS plot. |
Looking at the results shown in Figure 11, the image was split into 3 distinct classes based on the sample polygons overlayed on the multispectral image. The neural network appeared to have only required ten iterations to achieve a less than 0.1 root mean square (RMS) error as well-- which seems quick to my relatively inexperienced understanding of the neural network function in ENVI.
Conclusion
The expert system classification has proven to expertly distinguish differences and therefore, enhance classified imagery. Despite the inability to combine classes that were split in the knowledge engineer (ie. green vegetation [1 and 2] and agriculture[1 and 2]), which was most likely user error, the method adequately supplements the original classification to create a more accurate output and give the viewer a better understanding of the LULC within the study area.
As for the neural network, the objectives and output seem less clear. The resulting classes seem meaningless or at least indistinguishable as to what they are supposed to represent. The overall process and software was confusing to operate and derive meaningful results from. Having worked through the lab and read the support documents for what the system and function do, I still don't have a good grasp on how either work or what the point of using them is.
Overall, I was quite pleased, and frankly surprised, at the output generated from the expert system classification and could envision using that method for future projects having to do with classification. I would be interested to learn more about the functionality and various uses for employing a neural network classifier, as I felt that the scenario for this assignment didn't provide enough information to allow me to fully grasp the concepts of this classification method.
Sources
Department of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey [Landsat Satellite Images]. (n.d.).
ment of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey
Department of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey [Landsat Satellite Images]. (n.d.).
Department of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey [Landsat Satellite Images]. (n.d.).
Department of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey [Landsat Satellite Images]. (n.d.).
Department of Geography, University of Northern Iowa [Quickbird Highresolution Image]. (n.d.).
Earth Resource Observation and Science Center [Landsat Satellite Images]. (n.d.).
United States Geological Survey [Landsat Satellite Images]. (n.d.).